2016-12-05 11:36

1 客户需求
1.1 互动的事实
某银行作为国内大型商业银行,面对经营转型的战略目标的实现,需要深入了解企业运行的内外部环境、影响因子、参与主体特征等信息,而困扰在于银行如何收集客户各接触点信息,整合并真实反馈客户的意见、意愿,以制定合适的行动策略?
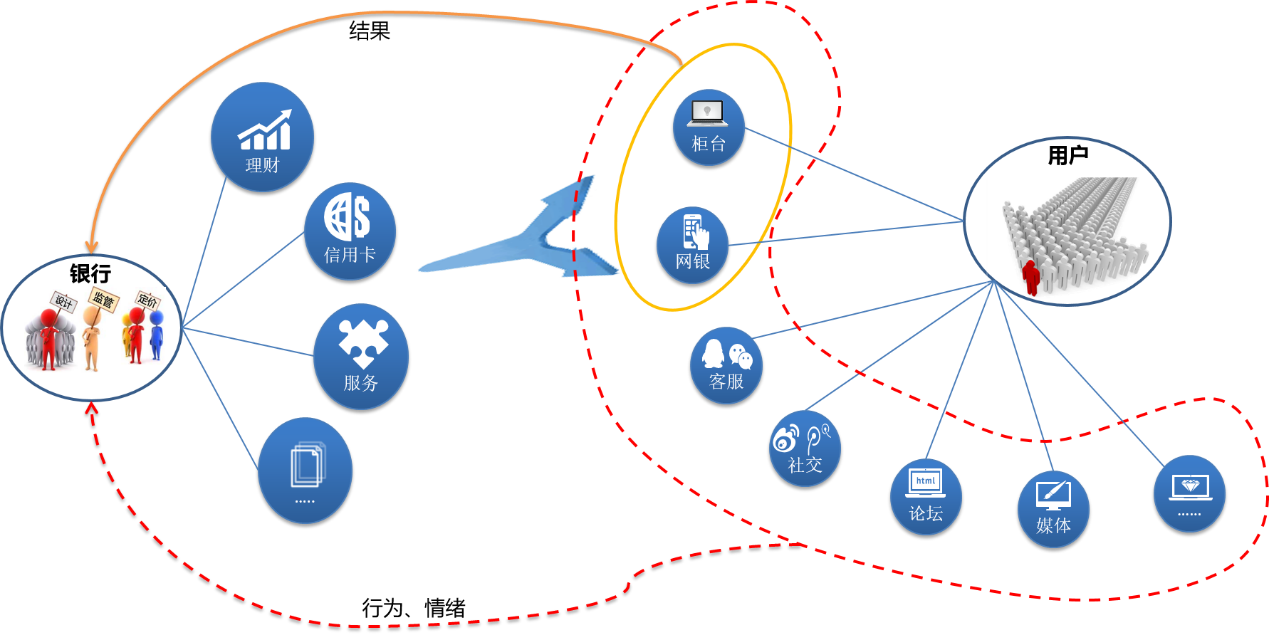
客户与银行总是在不断的互动当中,可能是为了寻求一个疑问的解答,可能是为了产品或服务的咨询等等。银行通常会提供多种官方沟通渠道,比如客服电话、客服微信公众号、官方论坛等等。客服人员总是尽可能的记录交流信息,并尽力为客户解决各种问题;但由于工作量大且繁杂,客服人员能为业务部门解决的烦恼也到此为止。
与产品或服务的互动不仅仅是出现在与银行的官方渠道交流中,在互联网上,在朋友圈中,在大众媒体里,都遍布着客户、社会大众、专家学者、舆论领袖的看法与意见,在脱离特定场景下的自由表达,是对银行产品和服务更为真实和客观的表述。
人们在与银行的关注或交流过程中流露出来的更深层次的业务需求,或者业务管理部门需要全局观察产品或服务的市场表现,往往只能通过事后的销售情况或调查机构设定的有限维度通过市场调查来获得。然而这是市场表现的真实原因吗?是客户切实的需求吗?更多的是来自资深业务人员的经验判断,越来越多的事实告诉我们,过渡依赖于经验,往往会导致极大的偏差。
被长期忽视的事实信息,可以为业务部门提供产品设计的观点支撑;可以为风险部门提供风险控制的考量素材;可以为营销部门提供直接精准且个性化的产品推荐;可为客服部门提供有针对性的人性化的个性服务等等;这些事实信息,在竞争越来越激烈的市场中愈加重要。
对事实信息获取手段的缺乏,是另外一个尴尬。
人们对银行产品或服务的关注表现形式可谓多种多样,有电话的通话录音,有客服代表略显随意的文本记录,有网络论坛的花样吐槽,有微博或圈子内的自拍晒图,有情绪各异的视频影像。
从体量庞大且表现形式复杂的数据中提取出适用于各个业务场景的事实信息,自然无法指望人肉完成,只能依靠快速准确的海量非结构化数据信息(情报)提取技术。
2 解决方案

2.1 技术的选择
处理非结构化数据,站在巨人的肩膀上总是个不错的选择。非结构化数据处理需要多样的处理技术手段,丰富的生态是必备的条件;有效的非结构化数据分析必然面临着巨大的数据体量,具备极强的横向扩展能力和灵活的数据处理能力也是必备条件。
单纯的非结构化数据存储和特定方向少量非结构化数据分析已经有了很多商业解决方案,但面对海量非结构化数据的存储、分析,选择Hadoop作为底层技术平台是我们综合多方面因素得出的最佳结论。
2.2 烟囱是一个过程
银行由很多业务部门组成,各个部门关注方向不同,对数据使用方式不同,对数据使用时间也不同,当业务部门有数据使用需求时,技术部门总被要求在最短时间内快、准、稳的实现业务需求。
解决一个算一个,是很多技术部门应对繁杂业务需求的策略之一,久而久之就会形成相同的数据原材料,相同的技术平台,仅仅因为不同业务需求和不同技术实施团队,为了更安全、更可控而建立了不同的物理实现,“烟囱”林立。这种局面,无论是管理层面、成本层面、资源利用率层面等来说,都不是最佳解决方案,基于Hadoop的集群式的应用更是如此。
2.3 平台化的努力
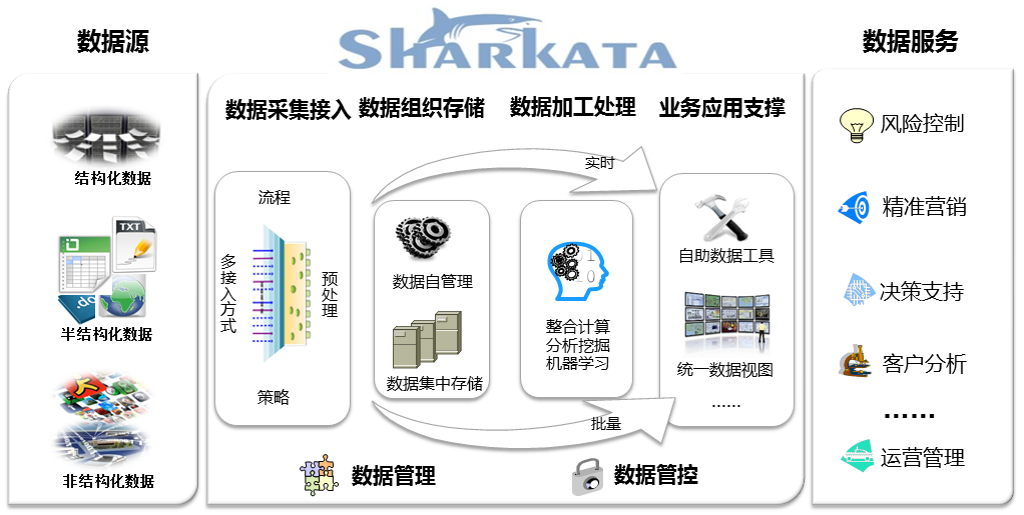
大数据的应用,一个技术团队无法解决全部业务问题,需要需要多个技术团队的参与,需要业务部门的参与。技术团队希望能以最少平台化是我们解决海量非结构化情报提取面临的第一个问题。通过平台化的规划与实施,我们实现了基于Hadoop的面向技术人员的PAAS数据分析平台和面向业务人员的SAAS业务分析平台。
在有严密的安全控制保障策略的前提下,实现了全银行数据、存储资源、计算资源、模型资源和算法资源的合理共享。业务人员不再为精通业务不懂技术从而无法准备数据的巧妇难为无米之炊式困扰而痛苦;技术人员也不在为日复一日年复一年重复应付业务数据准备的低价值劳动而无趣。
2.4 数据当作资产
数据当作资产不应该只是一个概念,平台化努力的另外一个成果就是数据资产自动化与可视化。
平台内所有数据的产生,都会有对应的数据资产记录。资产,既要包含数据的信息,也要进行数据的管理与控制。在数据信息方面,我们不但记录了数据的技术信息,也尽可能抽取了数据的业务信息;在数据管控控方面,我们对数据进行了检核控制,尽量确保平台内数据的有效性与可用性;全流程的数据生命周期更是整个平台的强制标准,保障了平台内垃圾数据的及时清理和合理的存储规则;数据安全访问的控制机制则为各个团队在数据保护和数据共享之间提供了灵活手段;数据资产信息的可视化展现与操作,则为数据使用普及到业务层面提供了基本保障。
2.5 一切都是为了使用
大数据的应用,需要对海量数据的有序使用。平台化的最终目的,就是为了实现数据使用更加简单有效。
通过图形化界面数据展现及订单式数据提取推送,实现了开发人员自主用数;通过PAAS化和SAAS化,屏蔽Hadoop底层技术,实现了开发人员和业务人员的简单化用数;通过实施工艺的完善和标准的统一,实现了数据使用快速推广的目的。
2.6 大数据分析
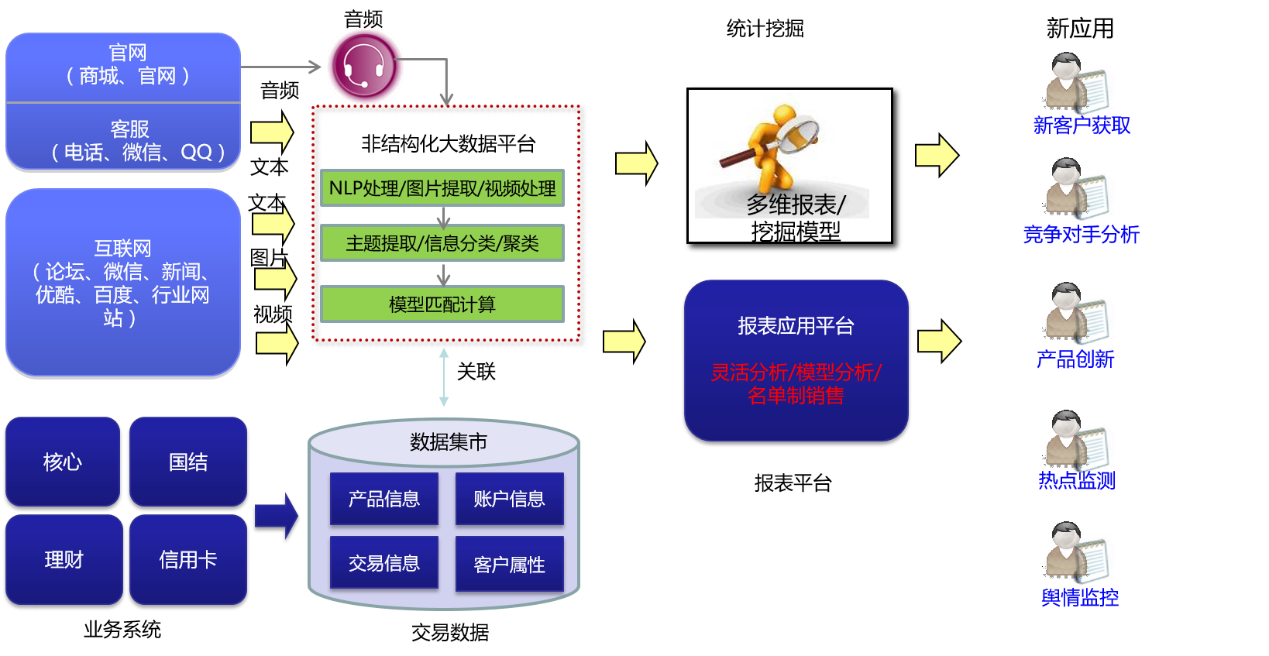
我们得到的各类互动数据在以300G/每天的体量不断累积,很多技术诸如NLP技术、图像识别技术等都需要极大的计算量,Hadoop/Spark分布式的存储与计算框架为我们带来了快速分析的可能性。
通过分布式改造算法与基于Hadoop/Spark开源组件的利用,我们实现了每日存量3小时内完成全部数据的主题提取、知识图谱提取和100万级业务模型计算,并实现了单条数据秒级实时数据的主题提取、知识图谱提取和100万级业务模型计算。
3 价值体现
3.1 分析成果的分享
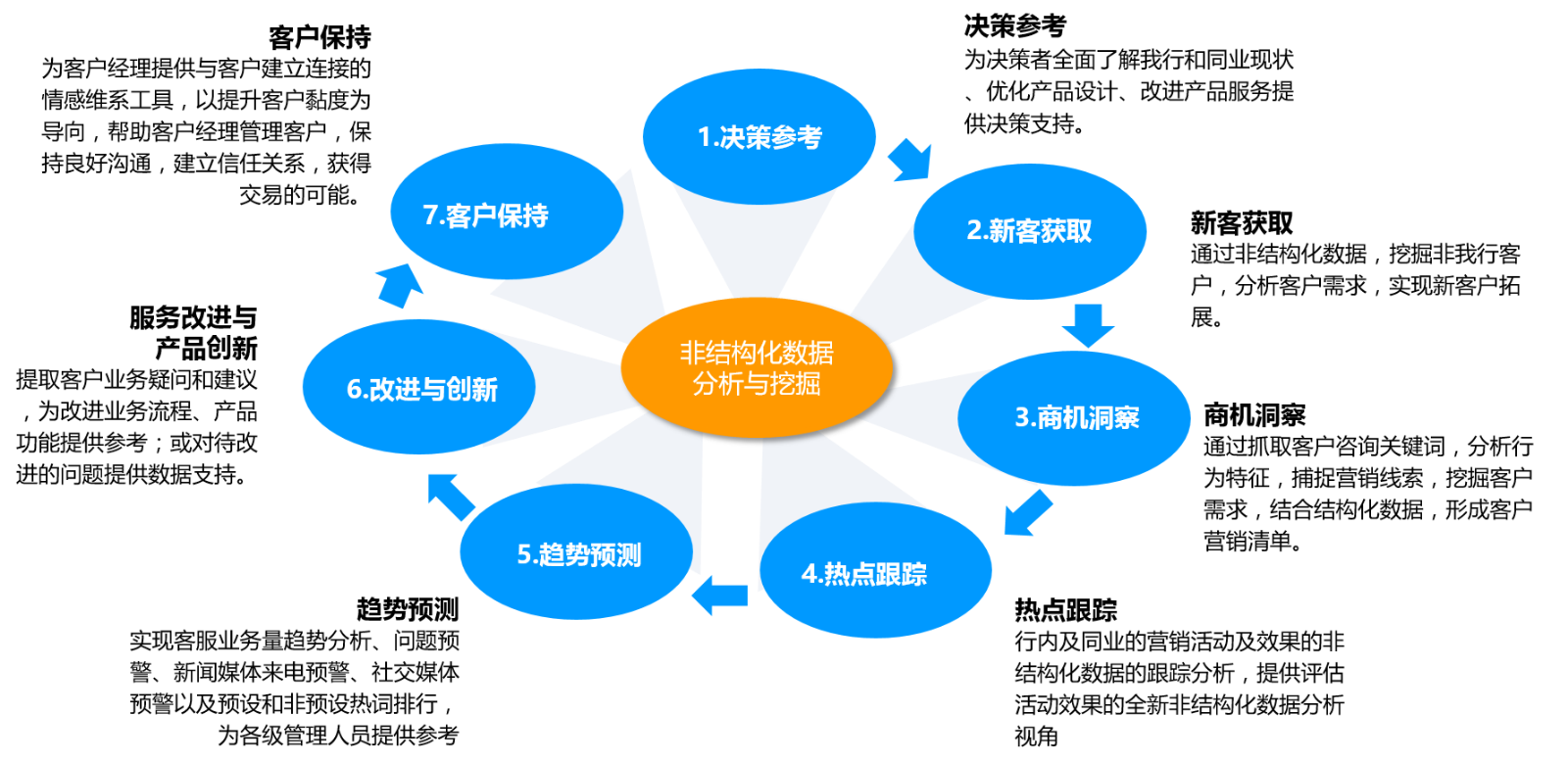
通过对互动数据的全面分析,业务部门得以掌握在以前常规运营中无法获取的关键事实信息,比如:
• 产品热度信息
全面的、客观的所有产品(包括竞争对手)热度信息,直接观察到银行产品在整个行业、整个产业链、类似产品线的热度位置。
• 竞争对手信息
以多个维度观察银行产品与竞争对手产品在客户客观感受上的差异,为产品调整或新产品设计提供依据。
• 潜客获取
获得了大量的产品购买意愿,无论是既有客户的交叉销售机会,还是全新客户的首次发现,都为营销人员提供了精准目标。
• 商机洞察
客户在各个场景所表现出来的爱好、倾向非常明确,银行产品并不能完全覆盖所有需求,但能快速推出符合呼声最高的产品迅速满足市场需求。
3.2 方案推广
项目完成后,我们将方案的推广分为两类:银行内部推广与新客户推广。
在银行内部,利用SAAS平台简单易用的操作,我们实现了直达一线业务人员的推广,将高级管理人员、业务专家、一线业务有效连接在一起,共同建模,共同用数,共享成果。
在新客户推广方面,不仅仅针对我们传统的银行企业客户有同质的推广价值,在证券行业客户、制造业客户、服务业客户方面也有类似需求。
4 结语
银行对大数据的应用既是一个系统性工程,也是由多个灵活性需求组成。企业级规划、平台级建设与小项目级快速实施,可帮助企业有序、逐步的实现大数据价值。
在大数据生态系统中的定位(业务方向):
先进数通借助于大数据领域的探索和沉淀,有效整合第三方大数据产品和工具,服务于客户。先进数通Sharkata有效地衔接了第三方大数据产品和工具厂商与客户。
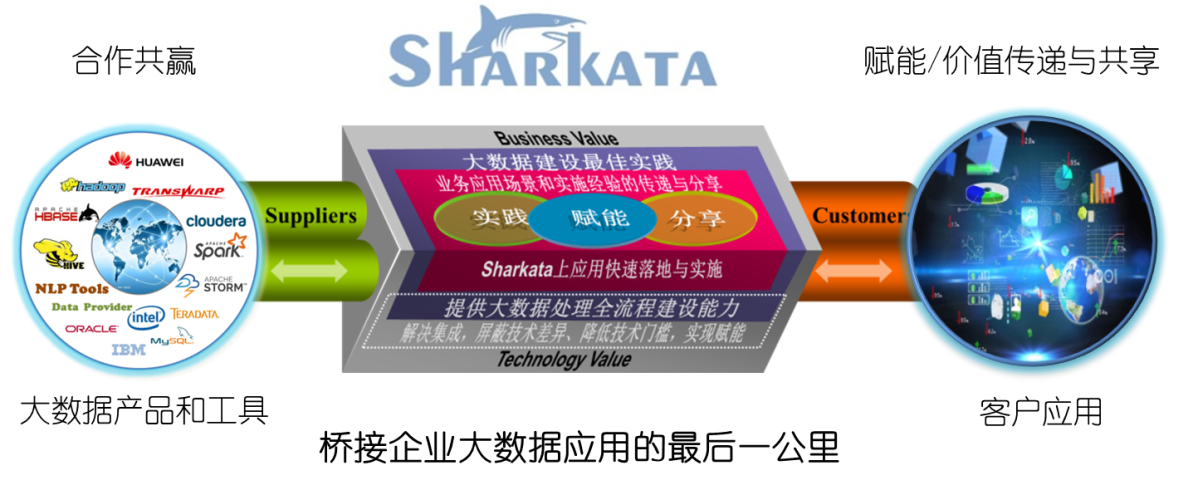
在大数据生态链上,先进数通是一家具有自有大数据产品的大数据服务提供商,致力于成为金融大数据能力建设的领航者。




